
近日,澳门新甫京官网在人工智能领域离线强化学研究中取得重要进展,相关成果以“Improving Generalization in Offline Reinforcement Learning via Adversarial Data Splitting”为题被人工智能领域国际顶级会议International Conference on Machine Learning(ICML 2024)接收。该论文第一作者为博士生王达博士,通讯作者为魏巍教授,同时得到了梁吉业教授和天津大学郝建业副教授的共同指导。此外,李琳博士和硕士生于骐衔也为该研究做出了贡献。
强化学习(Reinforcement Learning),作为机器学习的一大重要范式,是通过引导智能体在环境中进行探索,使其在反复的试错中学习到最优的行为策略。这一范式的迅猛发展,反映出人工智能领域对于构建能够自我学习、自主决策的智能系统的迫切需求。得益于计算能力的提升与数据处理技术的革新,强化学习正逐步成为提升智能体(包括机器人、自动驾驶汽车及智能软件代理等)自适应能力和任务执行效率的核心方法。
然而,在医疗、金融和工业等高风险领域,直接从环境中实时学习往往不可行。“离线强化学习”(Offline Reinforcement Learning)为这些存在安全风险、高成本或实施难度大的实时交互场景提供了解决方案。该技术允许智能体依赖预先收集的固定数据集进行学习,无需在线与环境交互获取新数据。这不仅拓展了强化学习的应用领域,而且能让智能系统在不影响现有环境的前提下,以数据为驱动优化决策策略。通过利用大量历史数据,离线强化学习能够改进决策流程,降低环境交互的风险与成本,从而在更多行业中实现强化学习技术的安全、可行应用。
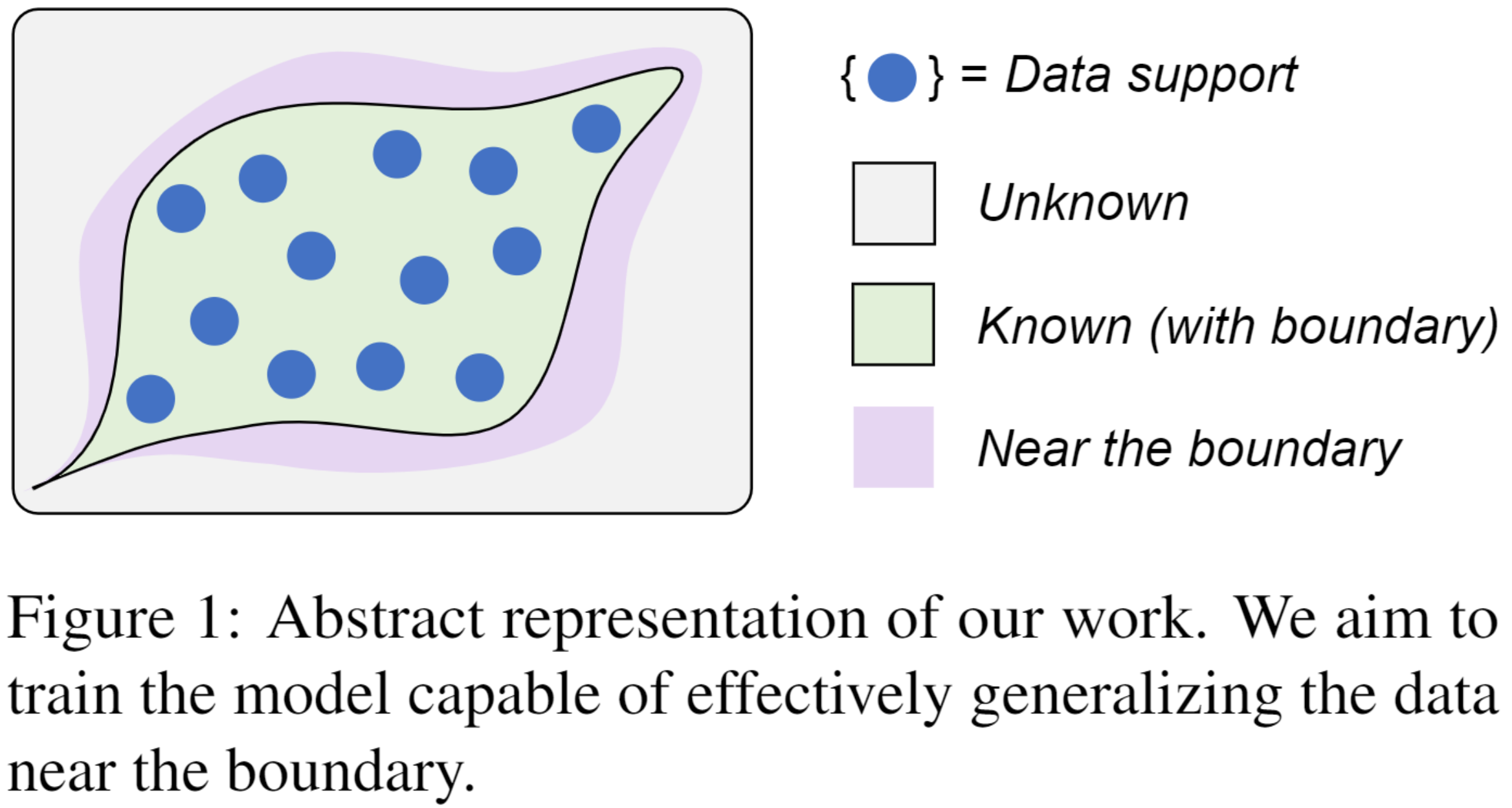
离线强化学习从静态数据集中学习最佳策略,其面临由于分布偏移导致out-of-distribution (OOD)数据被严重高估的基本挑战。已有工作逐渐将研究重心从抑制 OOD 高估转向避免从次优行为策略中过于保守地学习以提高泛化。然而,大多数方法显式地为OOD动作界定边界,这对于估计边界附近的数据是不够友好,一定程度上阻碍了其获得真实估计。为此,我们研究了如何放松OOD边界的硬性划分,自适应地从经验数据中提取知识,隐式地提高模型对附近未见数据的泛化能力(见图1)。
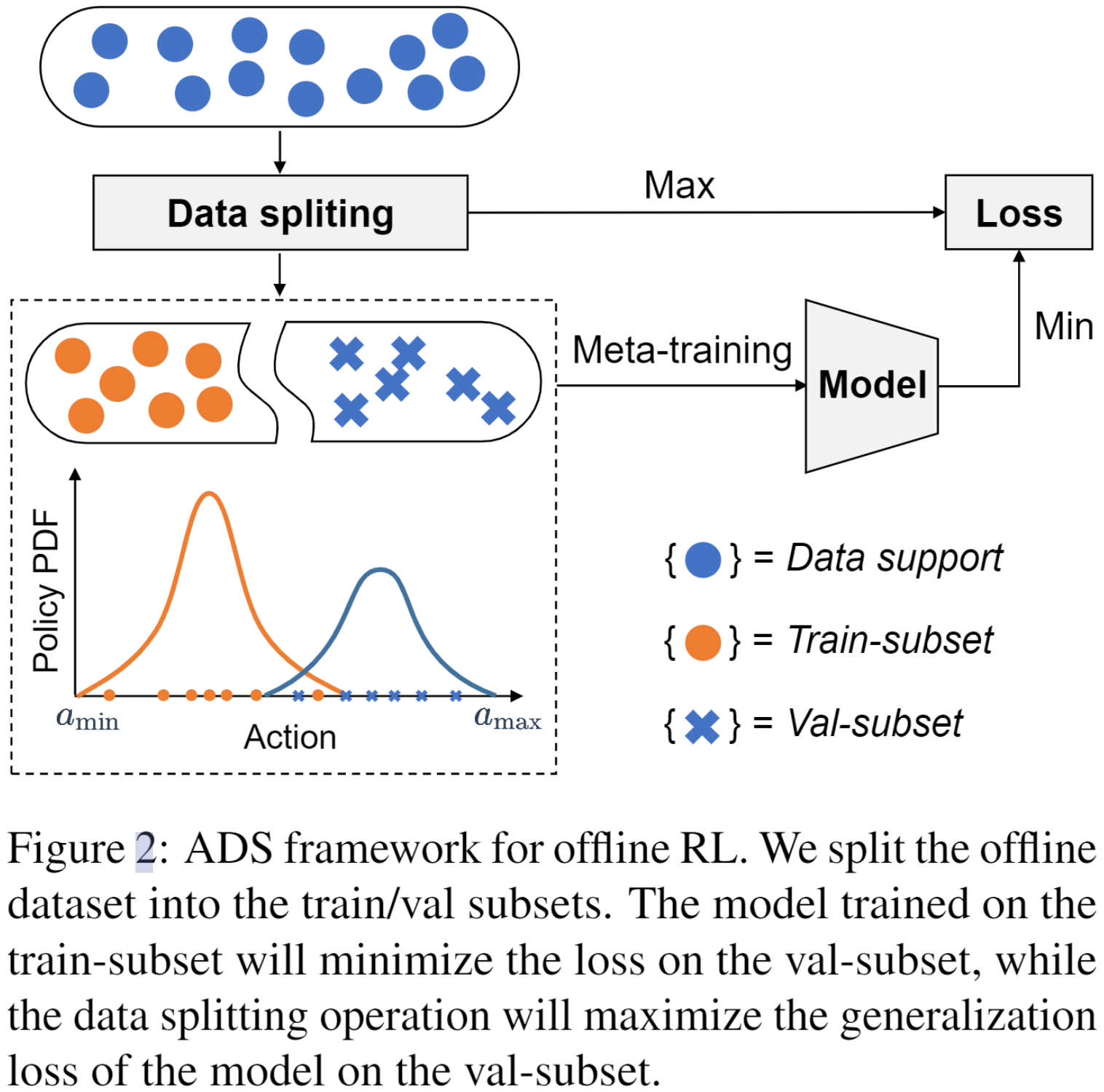
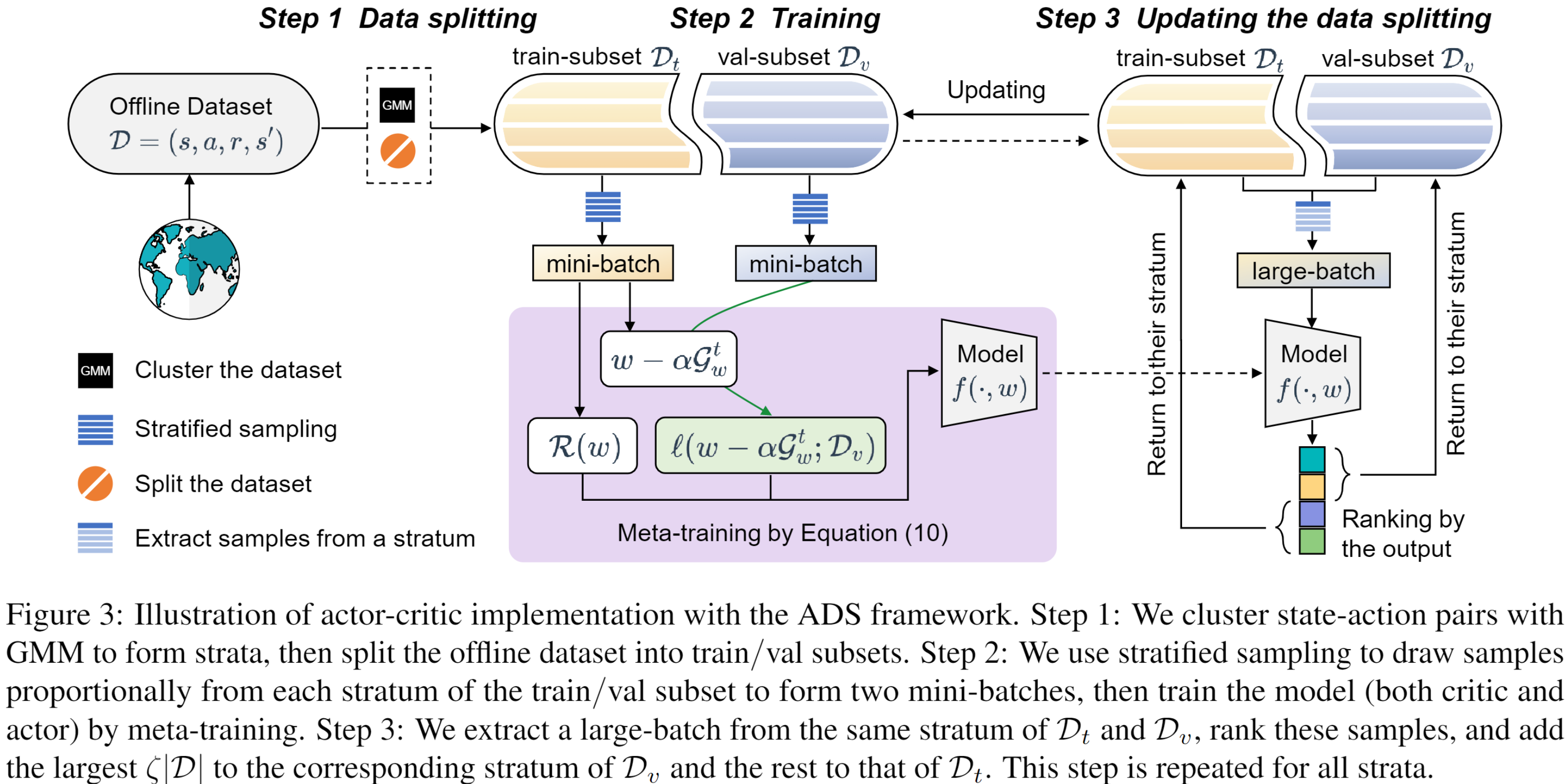
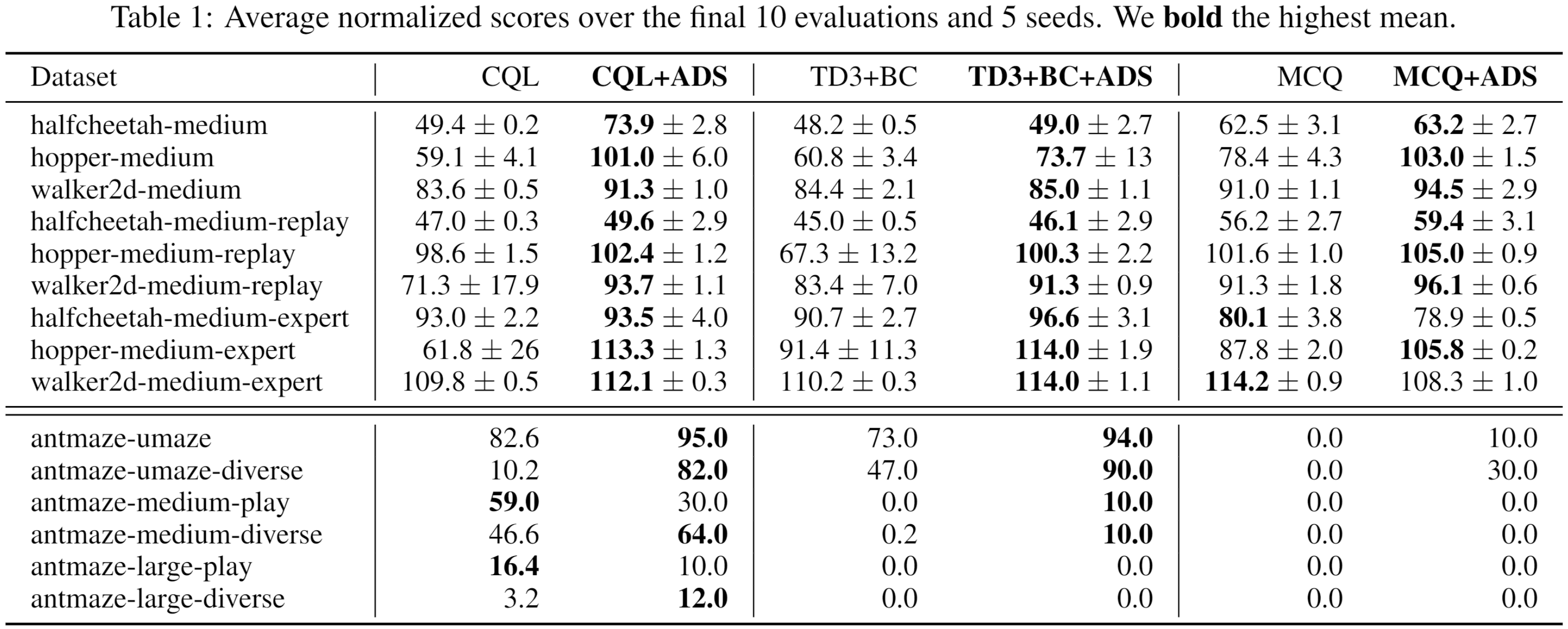
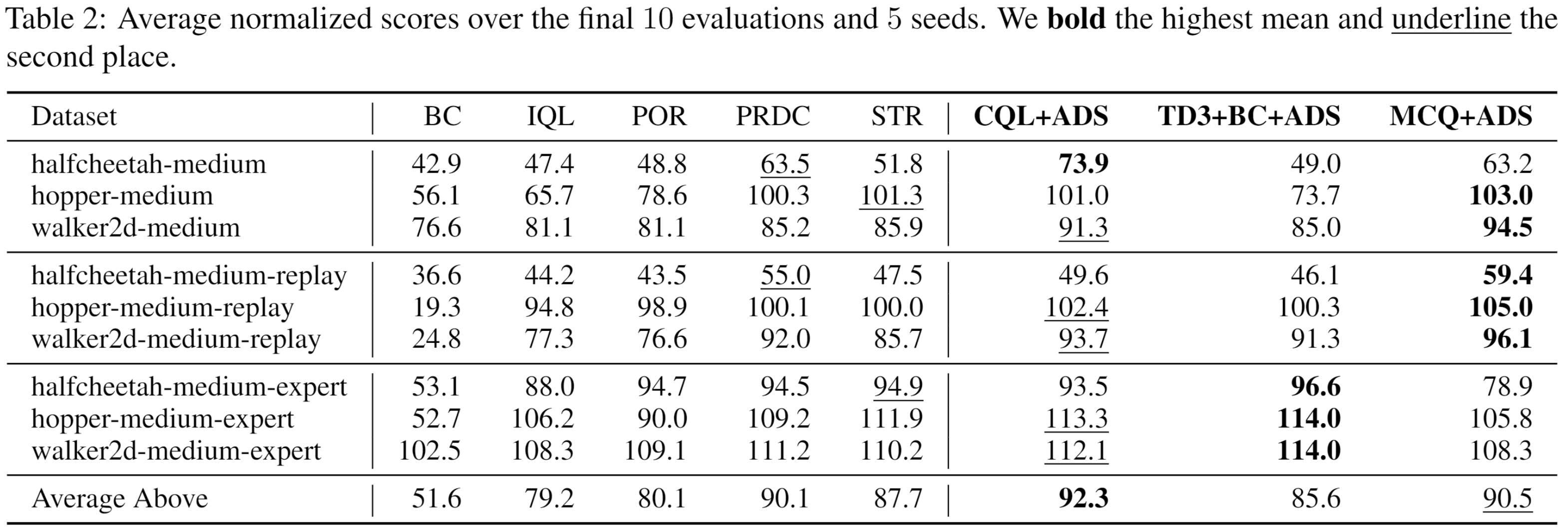
具体地,引入了一个对抗数据划分(Adversarial Data Splitting,ADS) 框架,该框架强制模型能够很好泛化从离线数据集拆分出的训练子集和验证子集模拟的分布偏移(见图2)。具体来说,ADS 被建模为受元学习启发的最小—最大优化问题,并通过迭代以下两个步骤来解决。首先,在训练子集上训练模型以最小化其在验证子集上的损失。然后,对抗性地生成具有最大分布偏移的训练/验证子集,使模型在该划分下无法泛化(详细算法流程见图3)。该研究推导出一个用于从理论上理解ADS的泛化误差界,并通过广泛的实验验证了方法的有效性(见表1和表2)。
该工作得到计算智能与中文信息处理教育部重点实验室、国家科技创新2030——“新一代人工智能”重大项目、国家自然科学基金重点项目、山西省“1331工程”计算机科学与技术重点学科建设项目的支持。