
近期,澳门新甫京官网机器学习团队在面向大数据的低质数据质量提升的理论与方法研究中取得了突破性进展,相关成果以“A Unified Sample Selection Framework for Output Noise Filtering: An Error-Bound Perspective”为题于2021年2月12日在机器学习与人工智能顶级期刊《Journal of Machine Learning Research》(简称JMLR,机器学习研究期刊)在线发表。该论文以澳门新甫京娱乐娱城平台为唯一单位,第一作者为姜高霞副教授,通讯作者为王文剑教授,梁吉业教授、钱宇华教授为合作作者。
大数据价值已被社会全面认可,基于机器学习的数据挖掘可进一步推动大数据的应用。但由于在数据的采集、传输、处理过程中存在的主客观原因,数据中会出现无标注、含噪声、不完整等质量问题,从而导致源于数据的知识和决策产生严重错误。目前已有一些方法处理数据的弱标注和填充等问题,但在大规模数据中很难保证没有任何噪声,如果出现部分噪声/错误标签,机器学习模型的预测结果会产生严重偏差。噪声过滤策略旨在找到噪声标签并将噪声样本去掉,避免模型受噪声标签的误导。虽然传统噪声过滤方法能够降低数据的噪声水平,但无法在理论和实际中确保模型预测能力的提升。
针对标签噪声问题,本论文首次从泛化误差界的角度提出一种噪声过滤框架,解决了回归任务中噪声过滤的有效性判别和样本自适应选择问题(见图1)。此框架明确了噪声环境下泛化误差界的影响因素,找到了判别噪声过滤有效性的准则,确定了噪声数据下模型泛化能力的最优目标函数,对提升数据质量和模型预测能力具有重要的科学意义。同时,此框架可以与任意的噪声估计结果相结合,形成新的过滤算法。这种过滤框架对于分类任务中的标签噪声处理具有借鉴意义,同时也为噪声环境下的鲁棒建模和数据预处理提供了新思路。
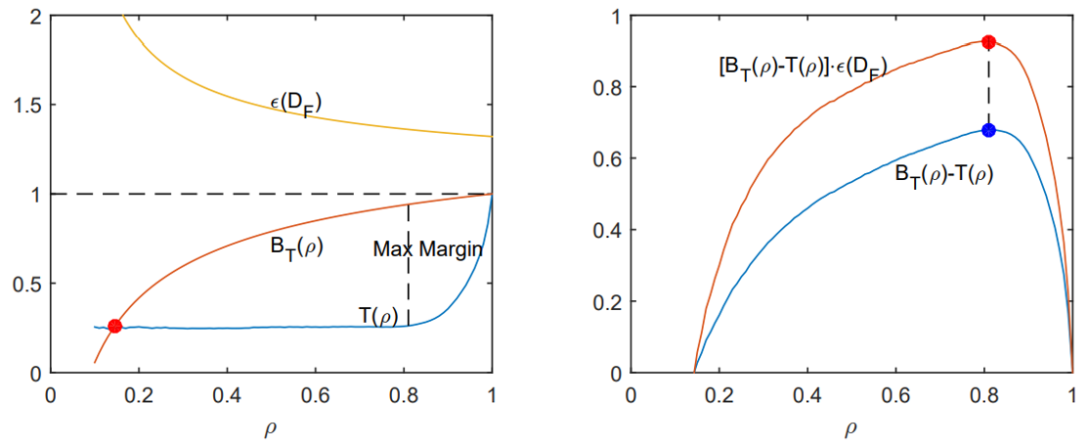
图1:(a) 噪声过滤的有效性判别(b) 噪声过滤的最优样本选择
研究团队还提出一种基于无偏噪声估计(见图2)的过滤方法,为含噪数据处理提供了一种切实有效途径。此方法在真实公开的年龄估计数据集上找到了明显不准确的年龄标签(见图3),并且提升了模型的预测性能。此算法的有效性也在标准数据集上得到了验证。
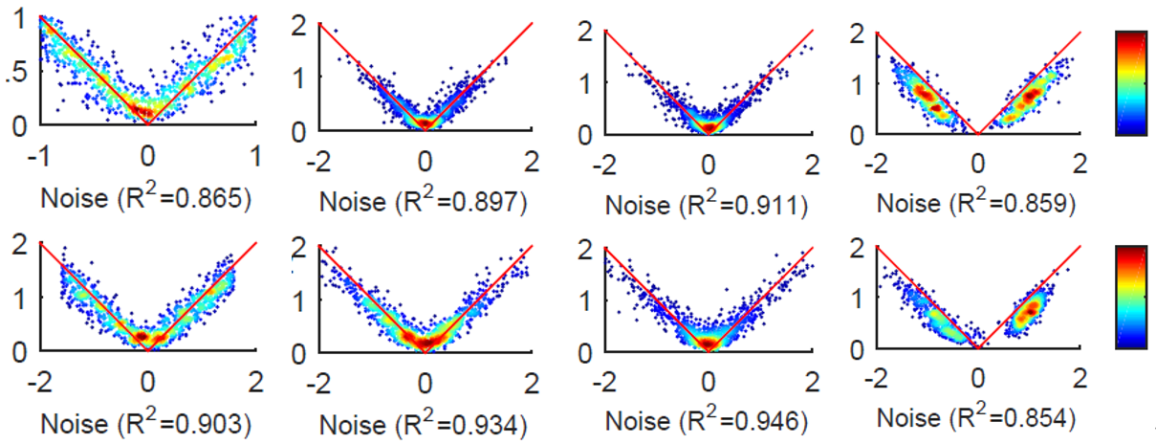
(a)均匀分布;(b)Gaussian分布; (c) Laplace分布; (d) 混合Gaussian分布。
图2 不同分布下的噪声估计结果
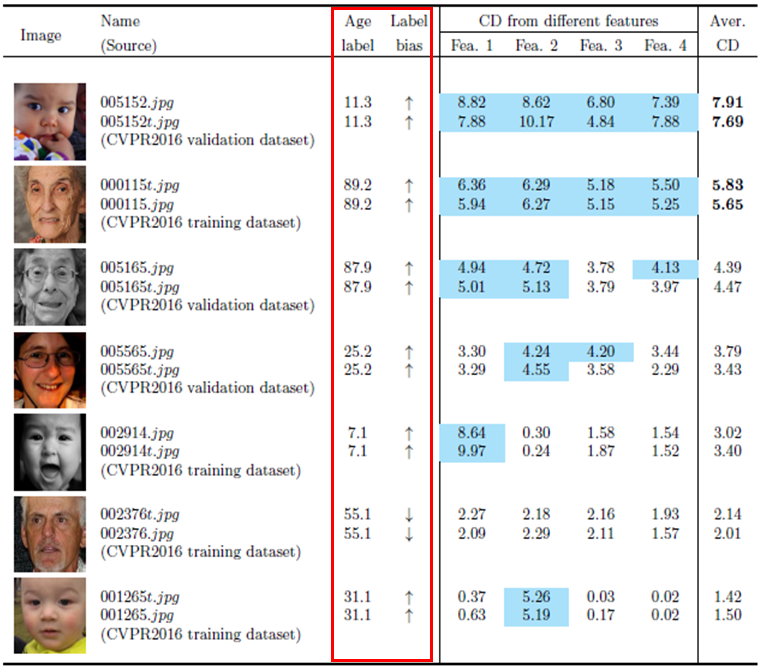
图3 在真实公开数据集上的年龄标签噪声检测(部分)结果
这项工作得到计算智能与中文信息处理教育部重点实验室、大数据挖掘与智能技术山西省协同创新中心、国家重点研发计划、国家自然科学基金、山西省“1331工程”重点学科建设计划的支持。
研究成果原文阅读链接:https://www.jmlr.org/papers/v22/19-498.html
JMLR建刊于2000年,是国际上公认的计算机领域顶级期刊之一,主要刊登机器学习与人工智能领域的高质量前沿研究成果。同时,JMLR也是中国计算机学会推荐的机器学习、人工智能和模式识别领域的四大A类期刊之一,2020年共发表论文252篇。